Hitting the inherent concurrency ceiling of Lua
I am always hesitant to say when I "started programming", because that phrase is usually doing more rhetorical work than technical work. There is a categorical difference between a ten-year-old reading Roblox scripts and vaguely understanding them, and a twelve-year-old who can maybe write programs with intent. Most people blur that distinction because it flatters their backstory, but for the sake of having a date, however, I will say 2020 - when I was twelve - was the point at which I began writing code rather than simply observing it.
Lua entered my life through Roblox, which at the time used a modified Lua runtime (before they introduced Luau, which I have many opinions on - but thats a topic for another day), and for a while I believed that Lua was something you used to glue together game objects inside a platform that everyone else thought was childish. In 2021 then, I discovered, via the Roblox developer forum of all places, that people were using Lua to write entire Discord bots, and that discovery was not trivial: it was the first time I saw Lua running outside of a sandbox, doing actual I/O, talking to the network, and behaving like a general-purpose language rather than a language to be embedded.
That led me to Luvit, Tim Caswell/Creationix's coro-suite (coro-http, coro-fs, etc.), SinisterRectus' Discordia, and eventually to my first genuinely large system: FUNK, a Discord music bot that aggregated YouTube and Spotify, streamed audio, and had enough users to start hitting API limits in uncomfortable ways. In hindsight, Lua was not the right language for a music bot either - I am currently rewriting FUNK in Go for almost the exact same reasons Rubiš is being rewritten - but the point is, that by the time Rubiš existed almost 4 years later, my entire mental model of "how servers work" was already shaped by Luvit: one event loop, many coroutines, everything asynchronous, nothing blocking if you can help it. To me, coroutines were nothing more than just "yeah put it in a coroutine, it will just do it in the background and I can do stuff here in the meantime".
That context matters heavily, because it explains why Rubiš v2 looks the way it does.
Rubiš, in its current production form (as of writing this blog post), is a Luvit service built on top of coro-http, backed by JayDB, and storing metadata for over 2.6 million scraps. The hot path - serving a "scrap" - is extremely efficient: a hash lookup into a Lua table, KeyStore, a fs.readFileSync on the content file, and a write back to the socket.
Under steady-state load, this yields p99 time-to-first-byte on the order of a couple of milliseconds. This is not an accident; LuaJIT's trace compiler, combined with a deliberately written allocation-light request path, makes this kind of workload almost embarassingly fast.
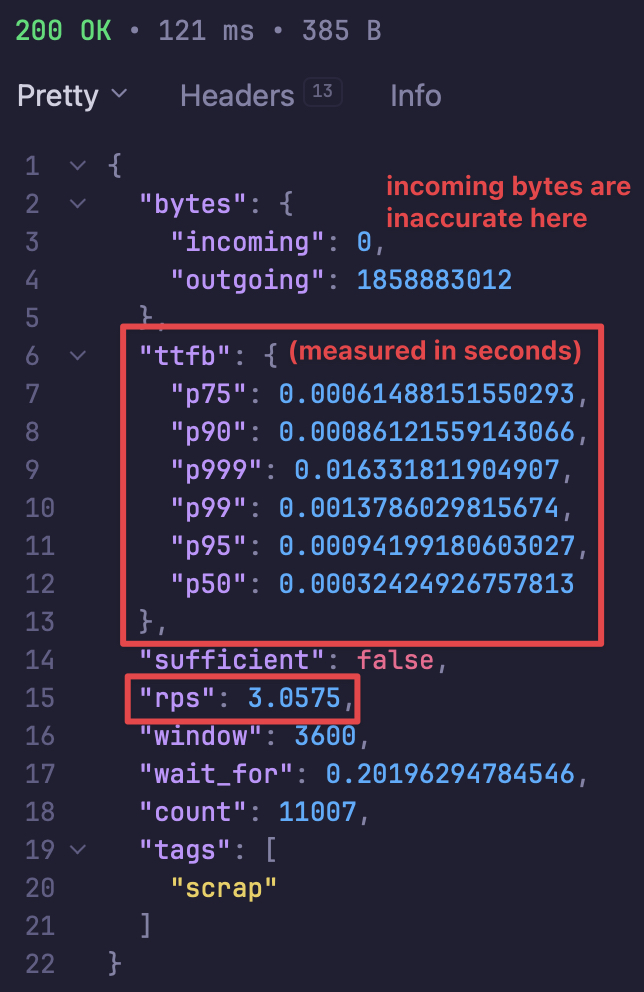
Recently when I added telemetry to Rubiš - an admin-only endpoint that computed percentiles, request counts, and crunched latency histograms - I accidentally re-discovered something far more interesting than any metric it returned. A single telemetry request, from my own IP, would freeze the entire server. Sockets would remain open, connections would continue to be accepted by libuv, but nothing would be processed until my singular telemetry call finished iterating over its dataset (which could have up to 250,000 entries), at which point a flood of queued requests would suddenly be handled in a burst. I was, in a very literal sense, able to technically DoS my own platform with a single HTTP request.
This reminded me that JayDB behaved the same way. I mention the addition of telemetry first though because that is the point where I genuinely realised that none of my over-engineered solutions would work, and thus the disillusionment with my "beloved" Lua began - even though I discovered the flaws of Lua through JayDB first, which I will talk about now.
Rubiš's metadata store is effectively a Lua table mapping scrap IDs to records; autosave consists of serialising that table - currently over 2.6 million entries, each with subfields - into a slightly modified version of MessagePack (jay3) and writing it to disk. This used to be plain JSON, which was catastrophically slow; MessagePack reduced the constant factors dramatically, but it did not change the fundamental problem: autosave is an \(\mathcal{O}(n)\) traversal of the entire database, and it runs synchronously inside the Lua VM. When \(n\) became large enough, that traversal would freeze the event loop for seconds, then tens of seconds, and eventually minutes.

It is tempting, when you see this behaviour, to reach for some usual suspects: garbage collection, I/O, "Lua being slow" (said no one ever). And yet, none of those explanations survive contact with the data. The request hot path remained fast and stable, there were no GC-driven long tails or any sawtooth-like memory patterns. Disk writes would absolutely never have been a bottleneck on Kavun Cloud servers. What was saturating was something much more boring and much more fundamental: the fact that Lua, in Luvit, (I say "in Luvit" just to clarify - either way, Lua is still single threaded even outside of Luvit), runs on one OS thread, with cooperative scheduling, and cannot preempt a long-running piece of CPU-bound work. In this case, an unbounded loop in a cooperative VM is practically indistinguishable from a complete deadlock.
So at this point, I tried to "cheat". Or rather, over-engineer myself out of an issue arising from over-engineering itself.
Logically, one may think: if MessagePack serialisation was what made JayDB autosave block the Lua state, then why not move it into C and run it on another OS thread? LuaJIT gives you its beautiful FFI, libuv gives you uv_async_t, and suddenly it is easy to imagine a world where Lua hands off the work, goes back to serving requests, and later gets a callback saying "your work is finished! tremendous!". I even built the thing: a shared library in C compiled as a dylib on macOS and an .so on Linux, loaded using ffi.cdef and ffi.load, exposing one big "serialise this" function that creates a new thread, serialises, and notifies Lua when the work is done.
What killed that idea however was not performance (but that matters too) - it was memory and threading semantics!
You cannot safely iterate over a Lua table from another OS thread. Lua's VM is not thread-safe, and sharing a live Lua object across threads is undefined behaviour at best and segfault-fuel at worst. That means the C side could not simply "walk the KeyStore" and serialise it on the fly. To do this correctly, we would first have to iterate over every single entry in KeyStore and copy it into a C-owned, "language-agnostic" structure, effectively duplicating the entire database in memory - and only then could a background C thread serialise that copy.
At which point the whole thing collapses under its own weight. The \(\mathcal{O}(n)\) walk was still being done - the very thing we were trying to avoid blocking the event loop. Memory usage now doubles. And you have added segfaults, ABI mismatches, and deployment hell on top. At most, the offload buys you constant-factor improvements, not architectural relief, and even if it had worked, it would have been the kind of system that nobody, not even I (with my love for systems design), would have enjoyed maintaining.
This was the point where it stopped being a Rubiš problem and became a "what am I even trying to do with Lua" problem.
We must understand the context behind Lua: it was designed in 1993, in Brazil, by the Tecgraf group at PUC-Rio, under economic conditions that were insanely unique: the country had heavy trade barriers and a strong incentive to produce domestic software rather than import tools from the US. Lua was not created to be a primary application language; it was created to be an embeddable, lightweight scripting language that could be integrated into larger systems written in C. When Cloudflare uses Lua in their WAF, or when Vercel uses LuaJIT at the edge, they are using it exactly as intended: embedded inside a host that owns the threads, the memory, and the lifecycle.
What Roblox, Luvit, and (by extension) Rubiš did was completely invert that relationship. We embedded the host into Lua, not the other way around. Lua effectively became the operating system.
So at that point, trying to embed C into a language written in C intended to be embedded to save itself is not just technically awkward; it is entirely, philosophically backwards.
Around the same time, while on holiday and thinking far too much, I found myself seriously considering turning my own programming language project - Nue - into "Lua, but with mixed concurrency models", so that I could keep the Lua ecosystem I loved while escaping the single-VM trap. Nue predates Rubiš by a long time; it was never meant to be a band-aid for one service. But I was genuinely willing to throw away hundreds of hours of design work, urgently implement a parser, compiler, and runtime, and warp the entire premise of the language just to rescue Rubiš.
The fact that I missed every self-imposed deadline for Nue during this period is, in hindsight, fortunate. If I had succeeded, I would have destroyed a language to patch a service. That is not engineering; that is panic with a type system.
Almost half a year later from that, and less than a month ago from now, I had the surreal experience of speaking directly with Tim Caswell - the person who more or less created Luvit, and who now works as a Principal Engineer at Vercel - about what Rubiš was doing, how I reached the architectural limits of Lua, and where everything was breaking. It was an engineer-to-engineer conversation with someone who has spent a significant portion of his life inside libuv and event loops. I explained the freezes, the autosaves, the FFI detour, the fact that my entire platform could be paused by a single long-running coroutine.
What made that conversation uncomfortable in a useful way was that Tim did not tell me I was wrong about Lua, nor did he try to rescue it as a universal platform. He told me that Vercel uses LuaJIT at the edge precisely because it is fast and embeddable, not because it should be running an entire product stack. In other words, the language was still doing exactly what it was designed to do; it was my architecture that had outgrown that design.
There is something psychologically different about reaching a conclusion like that after arguing it through with the person who built the tool, rather than after reading a blog post. It does not feel like capitulation. It feels like closure.
Go entered my life in a much less dramatic way: I clicked through half of the interactive tour on golang.org, opened GoLand, wrote a few small programs, and then almost immediately started replacing critical Numelon infrastructure with it. This was not a principled language shoot-out. It was simply the first tool I tried that made the freezing stop. Goroutines, preemptive scheduling, and true multi-core execution mean that you can do something expensive in the background without turning the rest of the platform into a statue.
Rubiš v3 is therefore not a rewrite because Lua failed, but rather a rewrite because Lua succeeded so well that it exhausted the domain it was designed for.
Ironically, Lua is still very much part of Numelon. Sklair, our HTML compiler, embeds Lua directly into templates via <lua> tags and pre/post-build hooks, which is almost comically close to Lua's original purpose: a small, fast, embeddable language living inside a larger host.
That feels less like abandoning Lua and more like finally putting it back where it belongs.